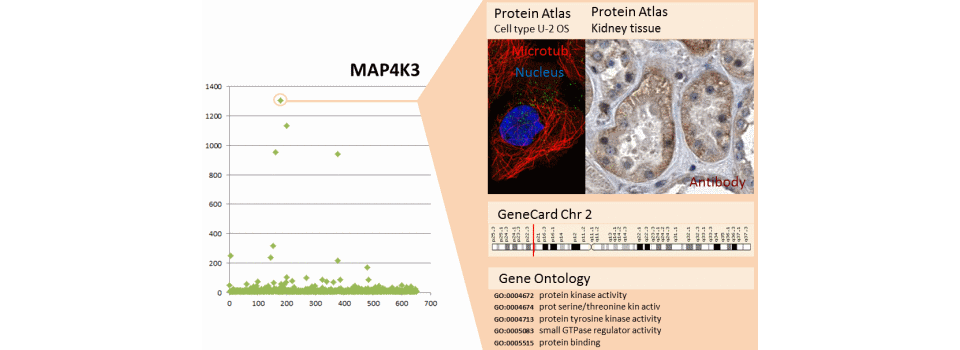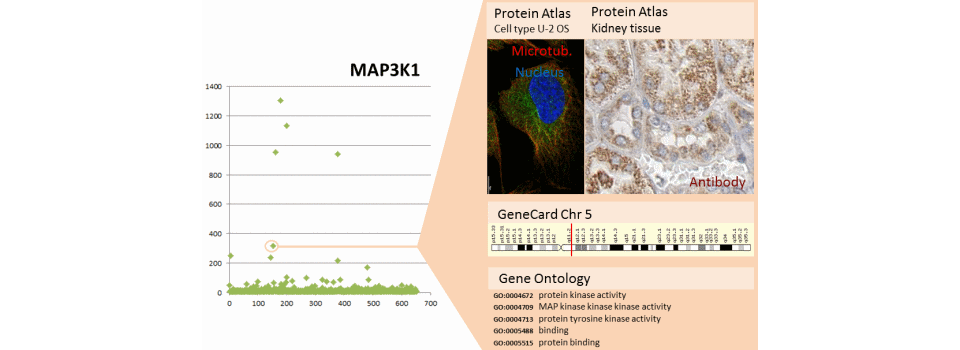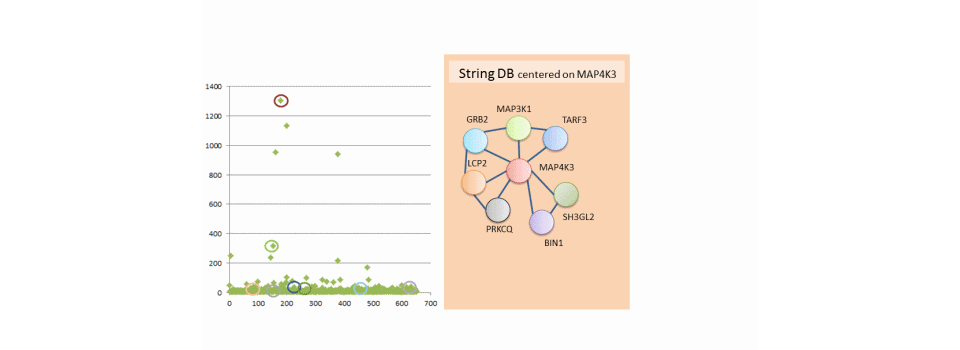
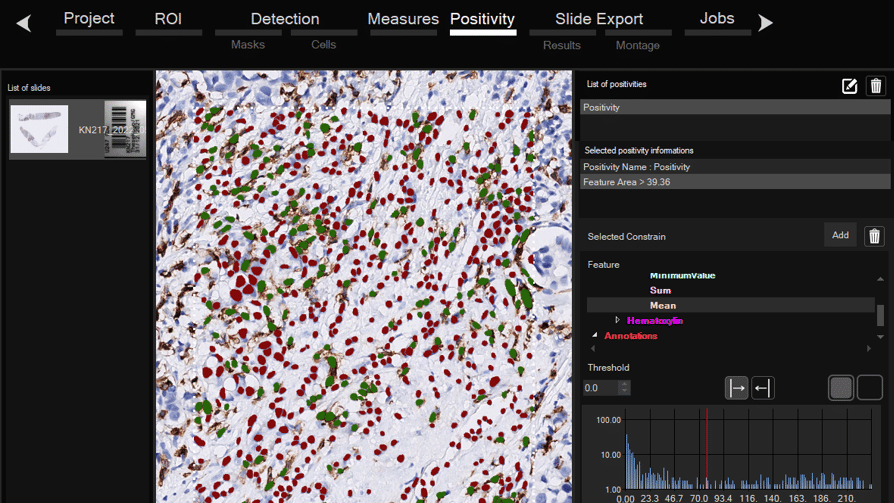
Logiciel pour échantillons histologiques
Détecte et quantifie automatiquement et facilement vos lames histologiques, sans nécessiter d’expertise en bio-informatique.
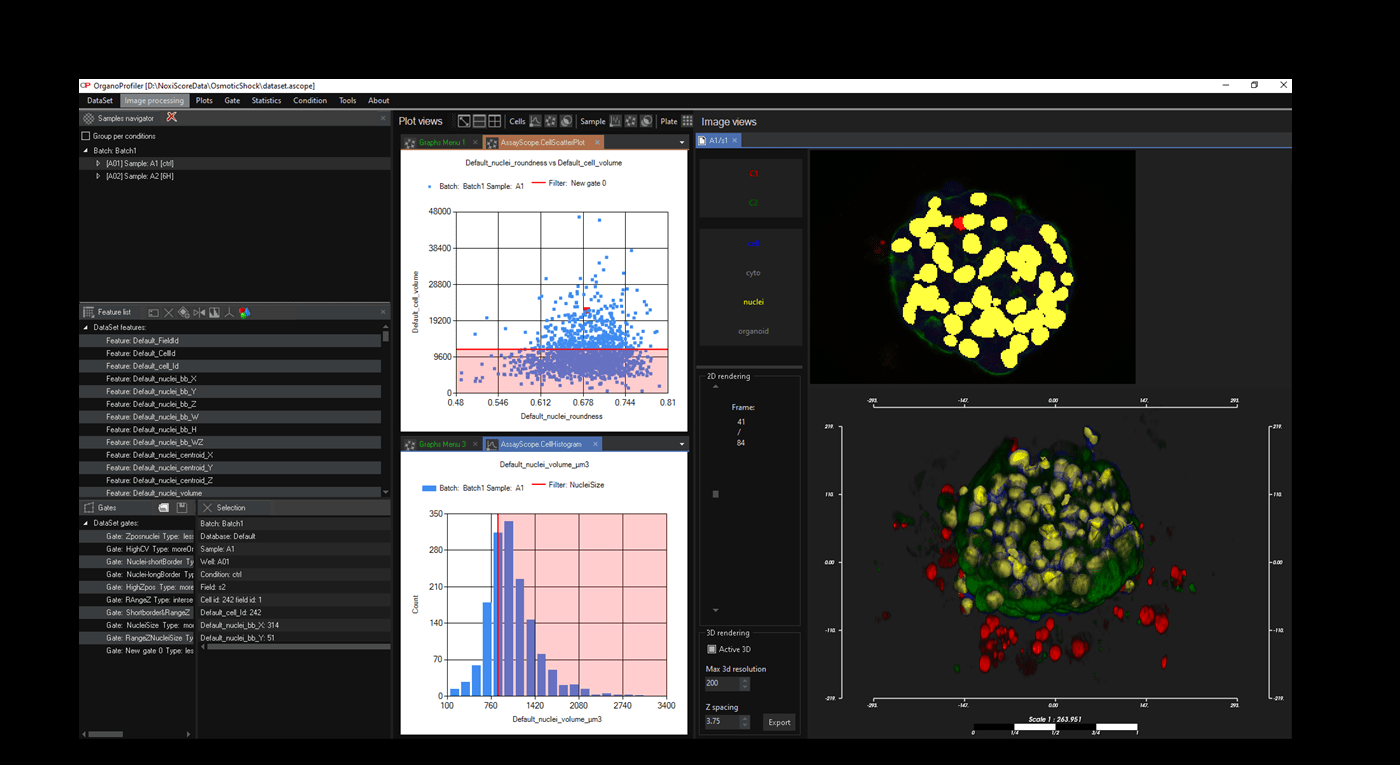
Logiciel pour organoïdes, sphéroïdes, cultures cellulaires et tissus 3D
Permet la segmentation 3D et l'analyse de criblage à haut contenu pour naviguer dans vos essais et étudier l'effet des médicaments
QUANTANALYTICS
Service d'analyse et de caractérisation
- Analyse d'image d'études cliniques
- Caractérisation des effets de médicaments
- Détection automatique d'événements rares

QUANTADEV
Développement de logiciel pour l'imagerie biomédicale
- Solutions customisées avec une ergonomie UIX
- IA pour automatisation
- Industrialisation des analyses en laboratoires